编者按:在现实生活中,普通用户很难编写合适的提示词(prompt)来指示 LLM 完成期望任务。用户提出的 queries 往往存在词汇不准确、缺乏语义信息等问题,导致 LLM 难以理解并生成相关的模型响应。因此,如何优化 queries ,增强 LLM 对各类 query 信息的精准理解能力,是当前亟待攻克的重要课题。
本文将探讨一些主流 Query Rewriting 技术,优化检索增强生成(RAG)系统的性能。
本文详细介绍和分析了以下几种 Query Rewriting 技术:
- Hypothetical Document Embeddings (HyDE):使用 LLM 生成与 query 高度相关的 hypothetical documents ,使其在嵌入空间中能与用户提交的 query 保持相似的语义属性。
- Rewrite-Retrieve-Read:先重写 query ,再检索内容生成模型响应。
- Step-Back Prompting:引导 LLM 从具体问题中抽象出高层次概念,有助于模型正确推理。
- Query2doc:结合 query 和 LLM 生成的 hypothetical documents ,构建语义层面的新 query 表征。
- ITER-RETGEN:迭代式检索生成,能够利用前一轮的大模型生成结果指导新一轮检索。
Query Rewriting 技术为 RAG 系统带来了新的优化方向,但也面临大量挑战(如 LLM 调用成本较高等),根据具体应用场景选择合适的优化方法组合是 RAG 系统优化的指导思想。
作者 | Florian June
编译 | 岳扬
在检索增强生成(Retrieval Augmented Generation,RAG)系统中,经常会出现与 user’s original queries(译者注:用户最开始输入的搜索问题或者其他需求。)有关的问题(例如,词汇不准确或缺乏语义信息),导致 RAG 系统难以理解。比如像 “2020 年 NBA 冠军是洛杉矶湖人队!请告诉我 langchain 框架是什么?” 这样的问题,如果直接搜索这个问题,可能会导致 LLM 给出错误的回答或无法回答的模型响应。
因此,将 user queries 的语义空间(semantic space)与系统中存储的文档的语义空间统一起来十分重要。 Query rewriting(译者注:对 user queries 进行重新构造或改写的过程,尽量修正 user queries 中可能存在的错误的、模糊的或不准确的部分。) 技术可以有效解决一问题。其在 RAG 中的作用如图 1 所示:

图 1: RAG 中的 Query rewriting 技术(由红色虚线框标记)。图片由作者提供。
从其在 RAG 系统中所处位置这一角度来看,Query rewriting 是一种 pre-retrieval 方法(译者注:在进行文档检索之前对 Query rewriting 进行重写或改进。)。该图大致说明了 Query rewriting 在 RAG 系统中的位置,在下文将介绍一些可以改进这一过程的算法。
Query rewriting 是将 queries 和系统中存储的文档的语义空间进行对齐(aligning the semantics of queries and documents)的关键技术。例如:
-
Hypothetical Document Embeddings,HyDE: 通过 hypothetical documents (并非实际存在的文档,而是虚构文档,用于对齐 queries 和系统中存储的文档的语义空间。)对齐 queries 和系统中存储的文档的语义空间。
-
Rewrite-Retrieve-Read: 提出了一种与传统的检索和阅读顺序不同的框架,侧重于使用 query rewriting 技术。
-
Step-Back Prompting: 允许 LLM 从抽象的概念或高层次的信息中进行推理和检索,而不仅仅局限于具体的细节或低层次的信息。
-
Query2Doc: 使用少量提示词或相关信息让 LLM 创建 pseudo-documents(译者注:并非真实存在的文档,用于辅助系统理解 user queries 或进行信息检索。)。然后将这些信息与用户输入的 queries 合并,构建新的 queries 。
-
ITER-RETGEN: 提出了一种将前一轮生成的结果与先前 query 相结合的方法。然后检索相关文档并生成新的结果。多次重复这个过程,直到获得最终结果。
让我们深入了解一下这些方法的细节。
01 Hypothetical Document Embeddings (HyDE)
《Precise Zero-Shot Dense Retrieval without Relevance Labels》[1]这篇论文提出了一种基于 Hypothetical Document Embeddings(HyDE)的方法,其主要流程如图 2 所示。
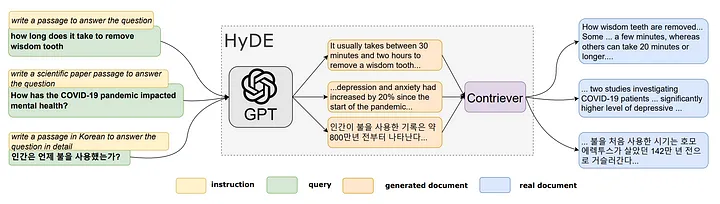
图 2:HyDE 模型示意图,图中展示了一些文档片段。HyDE 可为用户提交的所有类型的 queries 提供服务,而无需改变底层的 GPT-3 和 Contriever/mContriever 模型。Source:Precise Zero-Shot Dense Retrieval without Relevance Labels
该过程主要分为四个步骤:
- 使用 LLM 基于用户提交的 queries 生成 k 个 hypothetical documents (译者注:通过模型(如LLM)根据 queries 生成的虚假文档,模拟与 queries 相关的文档。)。这些生成的文档可能与实际事实不符,并且可能包含错误,但它们应该与相关文档类似。此步骤的目的是通过 LLM 解释用户提交的 queries 。
- 将生成的 hypothetical document 输入到编码器中,将其映射到一个密集向量 f(dk)。 我们认为编码器具有过滤功能,可以过滤掉 hypothetical document 中的噪声。此处,dk 表示第 k 个生成的文档,f 表示编码器操作。
- 使用给定的公式计算以下 k 个向量的平均值:

我们还可以将用户提交的 queries q 视为对某一问题进行的合理假设:

4. 使用向量 v 从文档库中检索相关内容。 如步骤 3 所述,该向量包含 user’s query 和所期望的特定信息,可以提高召回率(recall)。
我对 HyDE 的理解如图 3 所示。HyDE 的目标是生成 hypothetical documents(译者注:通过模型(如LLM)根据 queries 生成的虚假文档,模拟与 queries 相关的文档。),使得最终的查询向量(query vector) v 尽可能地在向量空间中与实际文档接近、对齐。

图 3:根据我的理解,HyDE 的目标是生成 hypothetical documents 。这样,最终的查询向量 v 会尽可能地与向量空间中的实际文档接近、对齐。图片由原文作者提供。
LlamaIndex[2] 和 Langchain[3] 都实现了 HyDE。下面以 LlamaIndex 为例进行说明。
将此文件[4]放置在 YOUR_DIR_PATH 。测试代码如下(我安装的 LlamaIndex 版本是 0.10.12):
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.indices.query.query_transform import HyDEQueryTransform
from llama_index.core.query_engine import TransformQueryEngine
# Load documents, build the VectorStoreIndex
dir_path = "YOUR_DIR_PATH"
documents = SimpleDirectoryReader(dir_path).load_data()
index = VectorStoreIndex.from_documents(documents)
query_str = "what did paul graham do after going to RISD"
# Query without transformation: The same query string is used for embedding lookup and also summarization.
query_engine = index.as_query_engine()
response = query_engine.query(query_str)
print('-' * 100)
print("Base query:")
print(response)
# Query with HyDE transformation
hyde = HyDEQueryTransform(include_original=True)
hyde_query_engine = TransformQueryEngine(query_engine, hyde)
response = hyde_query_engine.query(query_str)
print('-' * 100)
print("After HyDEQueryTransform:")
print(response)
首先,看看 LlamaIndex 中默认的 HyDE 提示词[5]:
############################################
# HYDE
##############################################
HYDE_TMPL = (
"Please write a passage to answer the question\n"
"Try to include as many key details as possible.\n"
"\n"
"\n"
"{context_str}\n"
"\n"
"\n"
'Passage:"""\n'
)
DEFAULT_HYDE_PROMPT = PromptTemplate(HYDE_TMPL, prompt_type=PromptType.SUMMARY)
HyDEQueryTransform 类[6]的代码如下,_def run 函数的目的是生成 hypothetical document ,在 _def run 函数中添加了三条调试语句,可监控 hypothetical document 的内容。
class HyDEQueryTransform(BaseQueryTransform):
"""Hypothetical Document Embeddings (HyDE) query transform.
It uses an LLM to generate hypothetical answer(s) to a given query,
and use the resulting documents as embedding strings.
As described in `[Precise Zero-Shot Dense Retrieval without Relevance Labels]
(https://arxiv.org/abs/2212.10496)`
"""
def __init__(
self,
llm: Optional[LLMPredictorType] = None,
hyde_prompt: Optional[BasePromptTemplate] = None,
include_original: bool = True,
) -> None:
"""Initialize HyDEQueryTransform.
Args:
llm_predictor (Optional[LLM]): LLM for generating
hypothetical documents
hyde_prompt (Optional[BasePromptTemplate]): Custom prompt for HyDE
include_original (bool): Whether to include original query
string as one of the embedding strings
"""
super().__init__()
self._llm = llm or Settings.llm
self._hyde_prompt = hyde_prompt or DEFAULT_HYDE_PROMPT
self._include_original = include_original
def _get_prompts(self) -> PromptDictType:
"""Get prompts."""
return {"hyde_prompt": self._hyde_prompt}
def _update_prompts(self, prompts: PromptDictType) -> None:
"""Update prompts."""
if "hyde_prompt" in prompts:
self._hyde_prompt = prompts["hyde_prompt"]
def _run(self, query_bundle: QueryBundle, metadata: Dict) -> QueryBundle:
"""Run query transform."""
# TODO: support generating multiple hypothetical docs
query_str = query_bundle.query_str
hypothetical_doc = self._llm.predict(self._hyde_prompt, context_str=query_str)
embedding_strs = [hypothetical_doc]
if self._include_original:
embedding_strs.extend(query_bundle.embedding_strs)
# The following three lines contain the added debug statements.
print('-' * 100)
print("Hypothetical doc:")
print(embedding_strs)
return QueryBundle(
query_str=query_str,
custom_embedding_strs=embedding_strs,
)
如下方式运行测试代码:
(llamaindex_010) Florian:~ Florian$ python /Users/Florian/Documents/test_hyde.py
----------------------------------------------------------------------------------------------------
Base query:
Paul Graham resumed his old life in New York after attending RISD. He became rich and continued his old patterns, but with new opportunities such as being able to easily hail taxis and dine at charming restaurants. He also started experimenting with a new kind of still life painting technique.
----------------------------------------------------------------------------------------------------
Hypothetical doc:
["After attending the Rhode Island School of Design (RISD), Paul Graham went on to co-found Viaweb, an online store builder that was later acquired by Yahoo for $49 million. Following the success of Viaweb, Graham became an influential figure in the tech industry, co-founding the startup accelerator Y Combinator in 2005. Y Combinator has since become one of the most prestigious and successful startup accelerators in the world, helping launch companies like Dropbox, Airbnb, and Reddit. Graham is also known for his prolific writing on technology, startups, and entrepreneurship, with his essays being widely read and respected in the tech community. Overall, Paul Graham's career after RISD has been marked by innovation, success, and a significant impact on the startup ecosystem.", 'what did paul graham do after going to RISD']
----------------------------------------------------------------------------------------------------
After HyDEQueryTransform:
After going to RISD, Paul Graham resumed his old life in New York, but now he was rich. He continued his old patterns but with new opportunities, such as being able to easily hail taxis and dine at charming restaurants. He also started to focus more on his painting, experimenting with a new technique. Additionally, he began looking for an apartment to buy and contemplated the idea of building a web app for making web apps, which eventually led him to start a new company called Aspra.
embedding_strs 是一个包含两个元素的列表(list)。列表中第一个元素是生成的 hypothetical document ,第二个元素是 original query 。它们被组合成一个列表,以便进行向量计算。
在本例中,HyDE 通过准确想象 Paul Graham(译者注:一位知名的科技创业者、程序员和作家, Y Combinator 的创始人之一,也是 Lisp 语言的支持者和倡导者之一。) 在 RISD(译者注:罗德岛设计学院(Rhode Island School of Design)的缩写,一所位于美国罗德岛州普罗维登斯的艺术和设计学院。2023年,在QS艺术与设计学院世界排名位列第3、全美第1。) 毕业之后所做的事情(请参见案例中的 hypothetical document ),大大提升了输出质量。从而改善嵌入向量(embedding)和最终模型输出结果的质量。
当然,HyDE 也有一些失败案例。对此感兴趣的读者可以通过访问这个链接[7]进行测试。
HyDE 方法看起来是无监督的,这种方法没有通过标注过的数据来训练任何模型,包括 generative model(译者注:其主要任务是从数据中学习数据的分布,然后可以用来生成类似于训练数据的新数据样本,通常用于生成图片、文本、音频等类型的数据。) 和 contrastive encoder(译者注:用于将数据编码为具有对比性特征的向量表示。在这种方法中,相似的样本在向量空间中被拉近,而不相似的样本则被推远。) 。
总而言之,虽然 HyDE 引入了一种新的 query rewriting 方法,但这种方法也存在一些局限性。这种方法不依赖于 query embedding 之间的相似性,而是强调一个文档与另一个文档的相似性。但如果语言模型对该特定垂直领域不熟悉,可能不会一直产生最佳的输出结果,可能导致错误内容增多。
02 Model-based 方法
该技术由论文《Query Rewriting for Retrieval-Augmented Large Language Models》[8]提出。该论文认为,在现实世界场景中,用户提交的 original query 可能并非都适合直接交给 LLM 进行检索。
因此,这篇论文建议我们应该首先使用 LLM 对 queries 进行重写。然后再检索内容和生成模型响应,而非直接从 original query 中检索内容并生成模型响应,如图 4(b) 所示。

图 4:从左到右,(a) 标准的 “retrieve-then-read” 方法,(b) 在 “rewrite-retrieve-read” pipeline 中将 LLM 作为 query rewriter,以及 © 在 pipeline 中使用可训练的 rewriter 。Source: Query Rewriting for Retrieval-Augmented Large Language Models[8].
为了说明 query rewriting 技术如何影响上下文检索(context retrieval)和预测(prediction)性能,再看看这个提示词示例:“2020 年 NBA 冠军是洛杉矶湖人队!请告诉我 langchain 框架是什么?” 通过重写(rewriting)得到了准确处理。
该流程可使用 Langchain[9] 实现,安装所需的基本库如下:
pip install langchain
pip install openai
pip install langchainhub
pip install duckduckgo-search
pip install langchain_openai
环境配置和 Python 库导入:
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
from langchain_community.utilities import DuckDuckGoSearchAPIWrapper
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
构建一个处理 query 的流程链并执行一些简单的 query 测试该流程链的功能和效果:
def june_print(msg, res):
print('-' * 100)
print(msg)
print(res)
base_template = """Answer the users question based only on the following context:
<context>
{context}
</context>
Question: {question}
"""
base_prompt = ChatPromptTemplate.from_template(base_template)
model = ChatOpenAI(temperature=0)
search = DuckDuckGoSearchAPIWrapper()
def retriever(query):
return search.run(query)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| base_prompt
| model
| StrOutputParser()
)
query = "The NBA champion of 2020 is the Los Angeles Lakers! Tell me what is langchain framework?"
june_print(
'The result of query:',
chain.invoke(query)
)
june_print(
'The result of the searched contexts:',
retriever(query)
)
运行结果如下:
(langchain) Florian:~ Florian$ python /Users/Florian/Documents/test_rewrite_retrieve_read.py
----------------------------------------------------------------------------------------------------
The result of query:
I'm sorry, but the context provided does not mention anything about the langchain framework.
----------------------------------------------------------------------------------------------------
The result of the searched contexts:
The Los Angeles Lakers are the 2020 NBA Champions!Watch their championship celebration here!Subscribe to the NBA: https://on.nba.com/2JX5gSN Full Game Highli... Aug 4, 2023. The 2020 Los Angeles Lakers were truly one of the most complete teams over the decade. LeBron James' fourth championship was one of the biggest moments of his career. Only two players from the 2020 team remain on the Lakers. In the storied history of the NBA, few teams have captured the imagination of fans and left a lasting ... James had 28 points, 14 rebounds and 10 assists, and the Lakers beat the Miami Heat 106-93 on Sunday night to win the NBA finals in six games. James was also named Most Valuable Player of the NBA ... Portland Trail Blazers star Damian Lillard recently spoke about the 2020 NBA "bubble" playoffs and had an interesting perspective on the criticism the eventual winners, the Los Angeles Lakers, faced. But perhaps none were more surprising than Adebayo's opinion on the 2020 NBA Finals. The Heat were defeated by LeBron James and the Los Angeles Lakers in six games. Miller asked, "Tell me about ...
结果表明,搜索到的上下文中,关于 “langchain” 的信息非常少。
现在就开始构建重写器(rewriter)以重写 search query (译者注:用户希望系统回答的问题或提供信息的关键字。)。
rewrite_template = """Provide a better search query for \
web search engine to answer the given question, end \
the queries with ’**’. Question: \
{x} Answer:"""
rewrite_prompt = ChatPromptTemplate.from_template(rewrite_template)
def _parse(text):
return text.strip("**")
rewriter = rewrite_prompt | ChatOpenAI(temperature=0) | StrOutputParser() | _parse
june_print(
'Rewritten query:',
rewriter.invoke({"x": query})
)
运行结果如下:
----------------------------------------------------------------------------------------------------
Rewritten query:
What is langchain framework and how does it work?
构建 rewrite_retrieve_read_chain 并使用重写后的 query 。
rewrite_retrieve_read_chain = (
{
"context": {"x": RunnablePassthrough()} | rewriter | retriever,
"question": RunnablePassthrough(),
}
| base_prompt
| model
| StrOutputParser()
)
june_print(
'The result of the rewrite_retrieve_read_chain:',
rewrite_retrieve_read_chain.invoke(query)
)
运行结果如下:
----------------------------------------------------------------------------------------------------
The result of the rewrite_retrieve_read_chain:
LangChain is a Python framework designed to help build AI applications powered by language models, particularly large language models (LLMs). It provides a generic interface to different foundation models, a framework for managing prompts, and a central interface to long-term memory, external data, other LLMs, and more. It simplifies the process of interacting with LLMs and can be used to build a wide range of applications, including chatbots that interact with users naturally.
至此,通过重写 query ,我们成功获得了正确答案。
03 STEP-BACK PROMPTING
“STEP-BACK PROMPTING[10]” 是一种简单的提示词技术,它能让学习者从包含了大量具体细节的问题中抽象、提炼出高层次的概念(high-level concepts)和某个领域中的基础规则或核心原理(basic principles)。 使得大型语言模型(LLMs)能够进行抽象,从包含具体细节的实例中提炼出高层次的概念和基本原则。其思想是将 “step-back problems” 定义为从最初的具体问题中派生出的更抽象的问题。
例如,如若某一个 query 中包含大量细节,LLM 很难检索到相关的事实来帮助解决任务。如图 5 中的第一个示例所示,对于物理问题“如果温度增加 2 倍,体积增加 8 倍,理想气体的压力 P 会发生什么变化?(What happens to the pressure, P, of an ideal gas if the temperature is increased by a factor of 2 and the volume is increased by a factor of 8 ?)” 当直接推理该问题时,LLM 的模型响应可能会偏离理想气体定律的第一原理(the first principle of the ideal gas law)。
同样,问题“Estella Leopold 在 1954 年 8 月至 1954 年 11 月期间去了哪所学校?(Estella Leopold went to which school between Aug 1954 and Nov 1954?)” 由于特定时间范围的限制,直接解决这一问题极具挑战性。

图 5:STEP-BACK PROMPTING 技术流程示意图,使用概念和原则来引导抽象(Abstraction)和推理(Reasoning)两个步骤。顶部:MMLU 高中物理课程内容示例,通过抽象得到理想气体定律的第一原理。底部:一些具体的信息(比如某人的教育经历细节)被 TimeQA 系统抽象概括为 “education history” 这个较高层次的概念。左侧:PaLM-2L 未能回答用户提出的原始问题。在推理过程的中间步骤中,Chain-of-Thought prompting 发生错误(使用红色标记)。右侧:PaLM-2L 通过 STEP-BACK PROMPTING 技术成功回答了问题。Source: TAKE A STEP BACK: EVOKING REASONING VIA ABSTRACTION IN LARGE LANGUAGE MODELS[10].
在这两种情况下,提出一个更宽泛的问题可以帮助模型有效地回答具体的 query 。我们可以询问“ Estela Leopold’s educational history. ”,而不是直接询问“Which school did Estela Leopold attend at a specific time,”。
这个更宽泛的问题概括了用户提出的原始问题,并且可以提供所有必要的信息来推断“Estela Leopold 在某一特定时间就读的学校(Which school Estela Leopold attended at a specific time.)”。值得注意的是,这些更宽泛的问题通常比原来的具体问题更容易回答。
从这些抽象概念(abstractions)中得出的推理结果(chain of thought)有助于防止在图 5(左)所示的 “chain of thought” 中间步骤中出现错误。
总之,STEP-BACK PROMPTING 包括两个基本步骤:
- Abstraction:首先,要求 LLM 提出一个有关高层次概念或原理(high-level concept or principle)的广泛问题,而不是直接回答 query 。然后检索与上述概念或原理(concept or principle)相关的事实。
- Reasoning:LLM 可以根据这些关于高层次概念或原则的事实,推导出用户提出的原始问题的答案。我们称之为抽象推理(abstract reasoning)。
为了说明 step-back prompting 如何影响上下文检索和预测的性能,下面使用 Langchain[11] 实现这一步骤。
环境配置和相关库的导入:
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate
from langchain_core.runnables import RunnableLambda
from langchain_openai import ChatOpenAI
from langchain_community.utilities import DuckDuckGoSearchAPIWrapper
构建一个处理 query 的流程链并执行一些简单的 query 测试该流程链的功能和效果:
def june_print(msg, res):
print('-' * 100)
print(msg)
print(res)
question = "was chatgpt around while trump was president?"
base_prompt_template = """You are an expert of world knowledge. I am going to ask you a question. Your response should be comprehensive and not contradicted with the following context if they are relevant. Otherwise, ignore them if they are not relevant.
{normal_context}
Original Question: {question}
Answer:"""
base_prompt = ChatPromptTemplate.from_template(base_prompt_template)
search = DuckDuckGoSearchAPIWrapper(max_results=4)
def retriever(query):
return search.run(query)
base_chain = (
{
# Retrieve context using the normal question (only the first 3 results)
"normal_context": RunnableLambda(lambda x: x["question"]) | retriever,
# Pass on the question
"question": lambda x: x["question"],
}
| base_prompt
| ChatOpenAI(temperature=0)
| StrOutputParser()
)
june_print('The searched contexts of the original question:', retriever(question))
june_print('The result of base_chain:', base_chain.invoke({"question": question}) )
其运行结果如下:
(langchain) Florian:~ Florian$ python /Users/Florian/Documents/test_step_back.py
----------------------------------------------------------------------------------------------------
The searched contexts of the original question:
While impressive in many respects, ChatGPT also has some major flaws. ... [President's Name]," refused to write a poem about ex-President Trump, but wrote one about President Biden ... The company said GPT-4 recently passed a simulated law school bar exam with a score around the top 10% of test takers. By contrast, the prior version, GPT-3.5, scored around the bottom 10%. The ... These two moments show how Twitter's choices helped former President Trump. ... With ChatGPT, which launched to the public in late November, users can generate essays, stories and song lyrics ... Donald Trump is asked a question—say, whether he regrets his actions on Jan. 6—and he answers with something like this: " Let me tell you, there's nobody who loves this country more than me ...
----------------------------------------------------------------------------------------------------
The result of base_chain:
Yes, ChatGPT was around while Trump was president. ChatGPT is an AI language model developed by OpenAI and was launched to the public in late November. It has the capability to generate essays, stories, and song lyrics. While it may have been used to write a poem about President Biden, it also has the potential to be used in various other contexts, including generating responses from hypothetical scenarios involving former President Trump.
结果显然不正确。开始构建 step_back_question_chain 和 step_back_chain,以获得正确的模型输出结果。
# Few Shot Examples
examples = [
{
"input": "Could the members of The Police perform lawful arrests?",
"output": "what can the members of The Police do?",
},
{
"input": "Jan Sindel’s was born in what country?",
"output": "what is Jan Sindel’s personal history?",
},
]
# We now transform these to example messages
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
step_back_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are an expert at world knowledge. Your task is to step back and paraphrase a question to a more generic step-back question, which is easier to answer. Here are a few examples:""",
),
# Few shot examples
few_shot_prompt,
# New question
("user", "{question}"),
]
)
step_back_question_chain = step_back_prompt | ChatOpenAI(temperature=0) | StrOutputParser()
june_print('The step-back question:', step_back_question_chain.invoke({"question": question}))
june_print('The searched contexts of the step-back question:', retriever(step_back_question_chain.invoke({"question": question})) )
response_prompt_template = """You are an expert of world knowledge. I am going to ask you a question. Your response should be comprehensive and not contradicted with the following context if they are relevant. Otherwise, ignore them if they are not relevant.
{normal_context}
{step_back_context}
Original Question: {question}
Answer:"""
response_prompt = ChatPromptTemplate.from_template(response_prompt_template)
step_back_chain = (
{
# Retrieve context using the normal question
"normal_context": RunnableLambda(lambda x: x["question"]) | retriever,
# Retrieve context using the step-back question
"step_back_context": step_back_question_chain | retriever,
# Pass on the question
"question": lambda x: x["question"],
}
| response_prompt
| ChatOpenAI(temperature=0)
| StrOutputParser()
)
june_print('The result of step_back_chain:', step_back_chain.invoke({"question": question}) )
其运行结果如下:
----------------------------------------------------------------------------------------------------
The step-back question:
When did ChatGPT become available?
----------------------------------------------------------------------------------------------------
The searched contexts of the step-back question:
OpenAI released an early demo of ChatGPT on November 30, 2022, and the chatbot quickly went viral on social media as users shared examples of what it could do. Stories and samples included ... March 14, 2023 - Anthropic launched Claude, its ChatGPT alternative. March 20, 2023 - A major ChatGPT outage affects all users for several hours. March 21, 2023 - Google launched Bard, its ... The same basic models had been available on the API for almost a year before ChatGPT came out. In another sense, we made it more aligned with what humans want to do with it. A paid ChatGPT Plus subscription is available. (Image credit: OpenAI) ChatGPT is based on a language model from the GPT-3.5 series, which OpenAI says finished its training in early 2022.
----------------------------------------------------------------------------------------------------
The result of step_back_chain:
No, ChatGPT was not around while Trump was president. ChatGPT was released to the public in late November, after Trump's presidency had ended. The references to ChatGPT in the context provided are all dated after Trump's presidency, such as the release of an early demo on November 30, 2022, and the launch of ChatGPT Plus subscription. Therefore, it is safe to say that ChatGPT was not around during Trump's presidency.
我们可以看到,通过将用户最开始给出的 query “stepping back”(译者注:将问题从一个具体或细节的层面转移到一个更为抽象或泛化的层面。) 到一个更抽象的问题,并同时使用经过抽象处理后的 query 和未经过抽象处理的 query 进行检索,LLM 提高了其沿着正确推理路径解决问题的能力。
正如 Edsger W. Dijkstra 所说,“通过抽象,我们不是为了让事物变得模糊或不确定,而是为了提取出问题的本质,并在更高的语义层次上得到更准确的理解和表达。(The purpose of abstraction is not to be vague, but to create a new semantic level in which one can be absolutely precise)”
04 Query2doc
《Query2doc: Query Expansion with Large Language Models》[12]介绍了 query2doc 这种方法。通过提示词引导 LLMs 生成 pseudo-documents ,然后将这些文档与 original query 结合起来创建一个新的 query ,如图 6 所示:
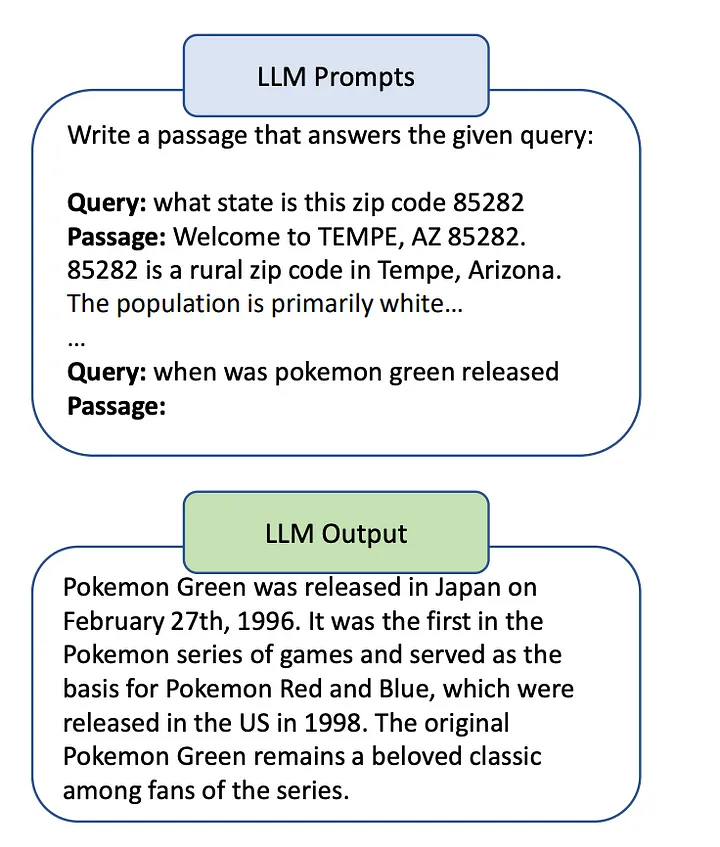
图6. query2doc 的 few-shot prompting技术示意图,由于篇幅原因,图中没有展示上下文内的所有内容。Source: Query2doc: Query Expansion with Large Language Models[12].
在 Dense Retrieval(译者注:与传统的基于检索的方法相比,这种方法利用预训练的语言模型(如BERT、RoBERTa等)来编码文档和 query,并计算它们之间的相似度。) 这种方法中,新的 query 用 q+ 表示,是最初的 query(q)和 pseudo-documents(d’)的简单连接,用 [SEP] 分隔:q+ = concat(q, [SEP], d’)。
Query2doc 认为,HyDE 隐含地假设真实文档(groundtruth document)和 pseudo-documents 用不同的词汇表达相同的语义,这对于某些 query 来说可能并不成立。
Query2doc 和 HyDE 之间的另一个区别是,Query2doc 会训练一个supervised dense retriever(译者注:在这种检索器中,通常会使用经过标注的训练数据来训练模型,并学习如何将 query 与相关文档进行匹配。有监督学习的方法可以帮助模型更好地理解 query 和文档之间的语义关系,从而提高检索的准确性和效率。),如这篇论文[12]所述。
目前,在 Langchain 或 LlamaIndex 中尚未发现 query2doc 的类似技术或工具。
05 ITER-RETGEN
ITER-RETGEN 这种方法会使用生成的内容来指导检索过程。它在 “Retrieve-Read-Retrieve-Read” 流程中反复使用 “retrieval-enhanced generation” 技术和 “generation-enhanced retrieval” 技术。

图 7:ITER-RETGEN 迭代地进行检索和生成。在每一次迭代中,ITER-RETGEN 都会利用前一次迭代的模型输出作为上下文,帮助检索更多相关的知识,这种方法有助于改进模型生成的响应(如本图中更正 Hesse Hogan 的身高案例)。为了简洁起见,本图中仅显示了两次迭代过程。实线箭头连接 query 和检索到的知识,虚线箭头表示检索增强生成流程。Source: Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy[13].
如图 7 所示,对于给定的问题 q 和检索语料库 D = {d}(其中 d 表示文档段落),ITER-RETGEN 会连续执行 T 次检索生成。
在每次迭代 t 中,会首先使用上一次迭代的生成结果 yt-1,将其与 q 结合,并检索出前 k 个段落。 然后,引导 LLM 模型 M 生成模型输出 yt,将检索到的文档段落(表示为 Dyt-1||q)和 q 纳入提示词中。 因此,每次迭代可以表述如下:
最后的输出 yt 将作为最终的模型响应产生。
与 Query2doc 类似,目前在 Langchain 或 LlamaIndex 中尚未发现 ITER-RETGEN 的类似技术或工具。
05 Conclusion
本文介绍了各种 query rewriting 技术,并提供了一些代码演示。
在实践中,这些 query rewriting 方法都可以尝试,至于使用哪种方法或方法组合,则取决于具体效果。
不过,无论采用何种 query rewriting 方法,调用 LLM 都会带来一些性能问题(译者注:例如速度较慢、资源消耗较大等。),这需要在实际使用中加以考虑。
此外,还有一些方法,比如 query routing ,将 queries 分解为多个子问题等,它们并不属于 query rewriting 技术,而是属于预检索方法(pre-retrieval methods),有机会会在后续文章中介绍这些方法。
如果您对 RAG 技术感兴趣,欢迎阅读本系列的其他文章!如有任何问题,请在评论区提出。
Thanks for reading!
——
Florian June
An artificial intelligence researcher, mainly write articles about Large Language Models, data structures and algorithms, and NLP.
END
参考资料
[1]https://arxiv.org/pdf/2212.10496.pdf
[2]https://docs.llamaindex.ai/en/stable/examples/query_transformations/HyDEQueryTransformDemo.html
[3]https://github.com/langchain-ai/langchain/blob/master/cookbook/hypothetical_document_embeddings.ipynb
[4]https://raw.githubusercontent.com/run-llama/llama_index/main/docs/examples/data/paul_graham/paul_graham_essay.txt
[5]https://github.com/run-llama/llama_index/blob/v0.10.12/llama-index-core/llama_index/core/prompts/default_prompts.py#L336
[6]https://github.com/run-llama/llama_index/blob/v0.10.12/llama-index-core/llama_index/core/indices/query/query_transform/base.py#L107
[7]https://docs.llamaindex.ai/en/stable/examples/query_transformations/HyDEQueryTransformDemo.html#failure-case-1-hyde-may-mislead-when-query-can-be-mis-interpreted-without-context
[8]https://arxiv.org/pdf/2305.14283.pdf
[9]https://github.com/langchain-ai/langchain/blob/master/cookbook/rewrite.ipynb
[10]https://arxiv.org/pdf/2310.06117.pdf
[11]https://github.com/langchain-ai/langchain/blob/master/cookbook/stepback-qa.ipynb
[12]https://arxiv.org/pdf/2303.07678.pdf
[13]https://arxiv.org/pdf/2305.15294.pdf
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接:
https://medium.com/@florian_algo/advanced-rag-06-exploring-query-rewriting-23997297f2d1